模型预测图
(点击返回顶部)
经济学家常要评估某政策或事件的效应。此政策可能实施于某国家或地区(省、州或城市)。为此,常使用“鲁宾的反事实框架”(Rubin’s counterfactual framework),即假想该地区如未受政策干预将会怎样,并与事实上受到干预的实际数据进行对比。常用解决方法是,寻找适当的控制组(control group),即在各方面都与受干预地区相似却未受干预的其他地区,以作为处理组(treated group,即受到干预的地区)的反事实替身(counterfactuals)。
1、合成控制法介绍
设想,要考察仅在A市实施的某政策效果,自然会想到以之相近的B市作为控制地区;但B市毕竟与A市不完全相同。或可用其他城市(B市、C市、D市)构成A市的控制组,比较B市、C市、D市与A市在政策实施前后的差别,此方法也称“比较案例研究”(comparative case studies)。但如何选择控制组通常存在主观随意性(ambiguity),而B市、C市、D市与A市的相似度也不尽相同。
为此,Abadie and Gardeazabal (2003)提出“合成控制法”(Synthetic Control Method)。其基本思想是,虽然无法找到A市的最佳控制地区,但通常可对若干大城市进行适当的线性组合,以构造一个更为优秀的“合成控制地区”(synthetic control region),并将“真实A市”与“合成A市”进行对比,故名“合成控制法”。合成控制法的一大优势是,可以根据数据(data-driven)来选择线性组合的最优权重,避免了研究者主观选择控制组的随意性。
合成控制法优点:
- 1) 作为一种非参数的方法,是对传统的双重差分法DID的拓展
- 2) 通过数据驱动确定权重,减少了主观选择的误差,避免了政策内生性问题
- 3) 通过对多个控制对象加权来模拟目标对象政策实施前的情况,不仅可以清晰地反映每个控制对象对“反事实”事件的贡献,同时也避免了过分外推
- 4) 可以对每一个研究个体提供与之对应的合成控制对象,避免平均化的评价,不至于因各国政策实施时间不同而影响政策评估结果,避免了主观选择造成的偏差
- 5) 研究者们可在不知道实施效果的情况下设计实验
2、我们的模型
动态时间规整(DTW)时间序列聚类原理:
- 1) 计算两个序列各个点之间的距离矩阵
- 2) 寻找一条从矩阵左上角到右下角的路径,使得路径上的元素和最小
矩阵从左上角到右下角的路径长度有以下性质:
- 1) 当前路径长度 = 前一步的路径长度 + 当前元素的大小
- 2) 路径上的某个元素(i, j),它的前一个元素只可能为以下三者之一:
- a) 左边的相邻元素 (i, j-1)
- b) 上面的相邻元素 (i-1, j)
- c) 左上方的相邻元素 (i-1, j-1)
假设矩阵为M,从矩阵左上角(1,1)到任一点(i, j)的最短路径长度为Lmin(i, j)。那么可以用递归算法求最短路径长度。
类似地, 迁移到消费金额序列中,选取156个有明确消费券发放日期的城市的消费金融/笔数数据,对其归一化并转为相同长度的时间序列(虽然DTW本身性质适用于不同长度的时间序列,但在window.type上受限),之后应用DTW算法对其进行聚类。
合成控制法部分:
- 1) 预测控制变量:城市迁入指数、城市迁出指数、城内出行强度
- 2) 被解释变量:城市在地消费总金额
- 3) 关系:日频城市迁入/迁出指数以及城内出行强度数据反映城市经济状况以及以及疫情防控力度,进而影响城市在地消费总金额
安慰剂检验:
- 1) 在比较案例研究中,由于潜在的控制地区数目通常并不多,故不适合使用大样本理论进行统计推断。为此,Abadie et al. (2010)提出使用“安慰剂检验”(placebo test)来进行统计检验,这种方法类似于统计学中的“排列检验”(permutation test),适用于任何样本容量。
- 2) 依次将donor pool中的每个城市作为假想的处理地区(假设也在2020年5月1日发放消费券),而将南充作为控制地区对待,然后使用合成控制法估计其“消费刺激效应”,也称为“安慰剂效应”。通过这一系列的安慰剂检验,即可得到安慰剂效应的分布,并将南充的处理效应与之对比。
PVAR面板向量自回归模型:
Holtz-Eakin(1987)最早利用利用PVAR模型分析面板数据的内生性变量之间的互动关系,其研究的是面板数据的向量自回归模型,即将所有的变量统一视为内生变量,分析各个变量及其滞后项之间的关系。PVAR模型利用面板数据既能够有效解决个体异质性问题,又能够充分考虑个体和时间效应。
在实证分析中面板数据包含了更多时间的维度的数据,可以利用更多的信息进行分析研究问题的动态关系,同时能够通过截距项来捕捉数据动态调整过程中的个体差异,有效减少了数据产生的偏误。面板数据具有时间和截面空间的两个维度,从而分享了横截面数据和时间序列数据的优点,另外,由于具有更多的观察值,其推断的可靠性也有所增加。
PVAR 继承了 VAR 模型的优点,将研究变量视为内生变量,并将每一个内生变量作为系统中所有内生变量滞后值的函数,提供丰富的结构从而捕获数据的更多特征。此外,PVAR 模型允许数据中存在的个体效应与异方差性,由于大量截面数据的存在,模型允许滞后系数随时间变化,放松了数据的时间平稳性要求。
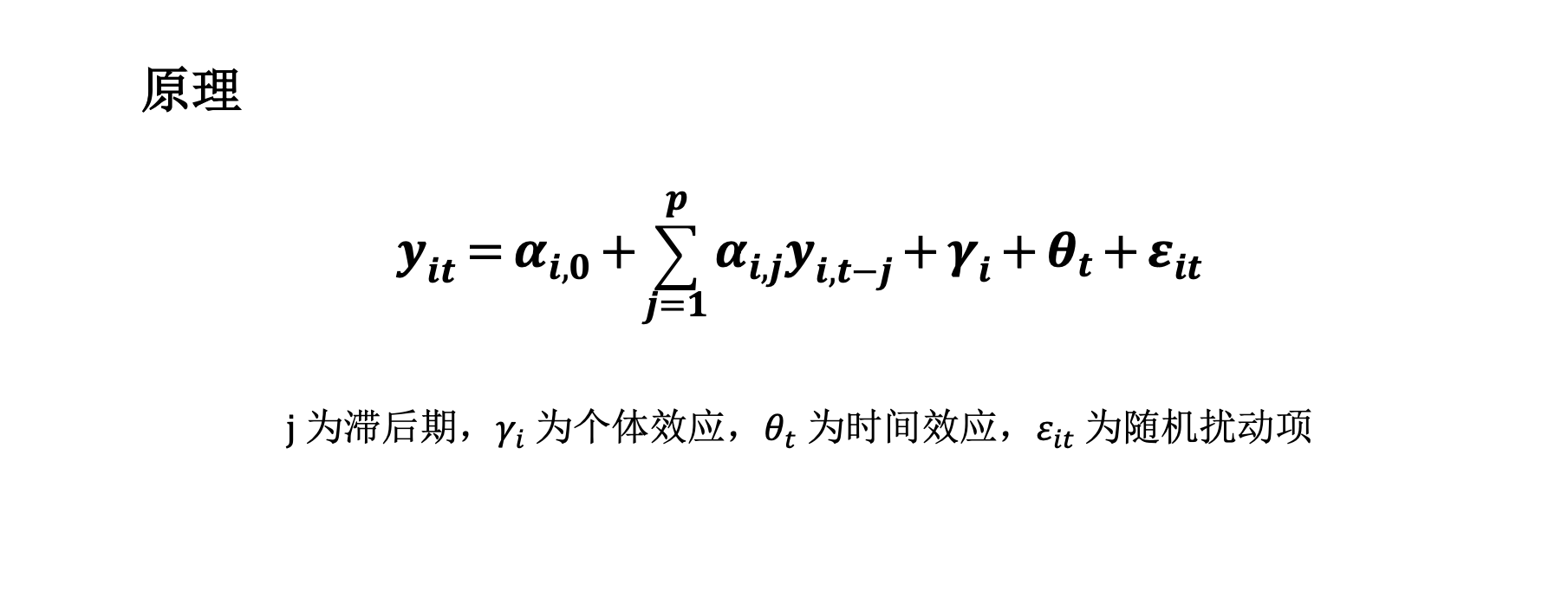
3、模型展示
其中以南充市为例,首先针对156个有明确消费刺激(政府发放消费券)起止日期的城市的消费金额数据这组时间序列聚类
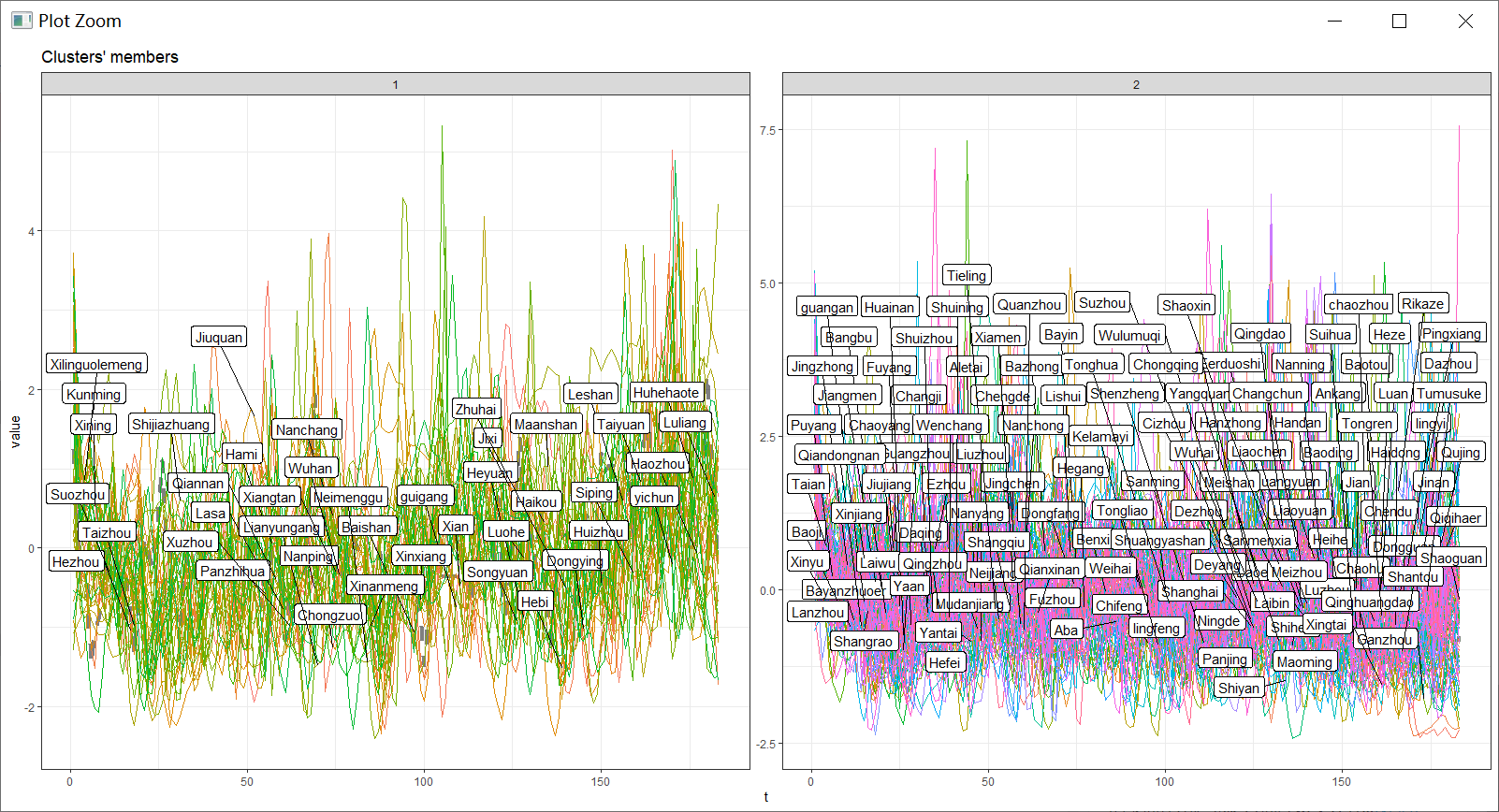
图1为156个城市的聚类结果
图2为时间序列聚类的prototype
 |
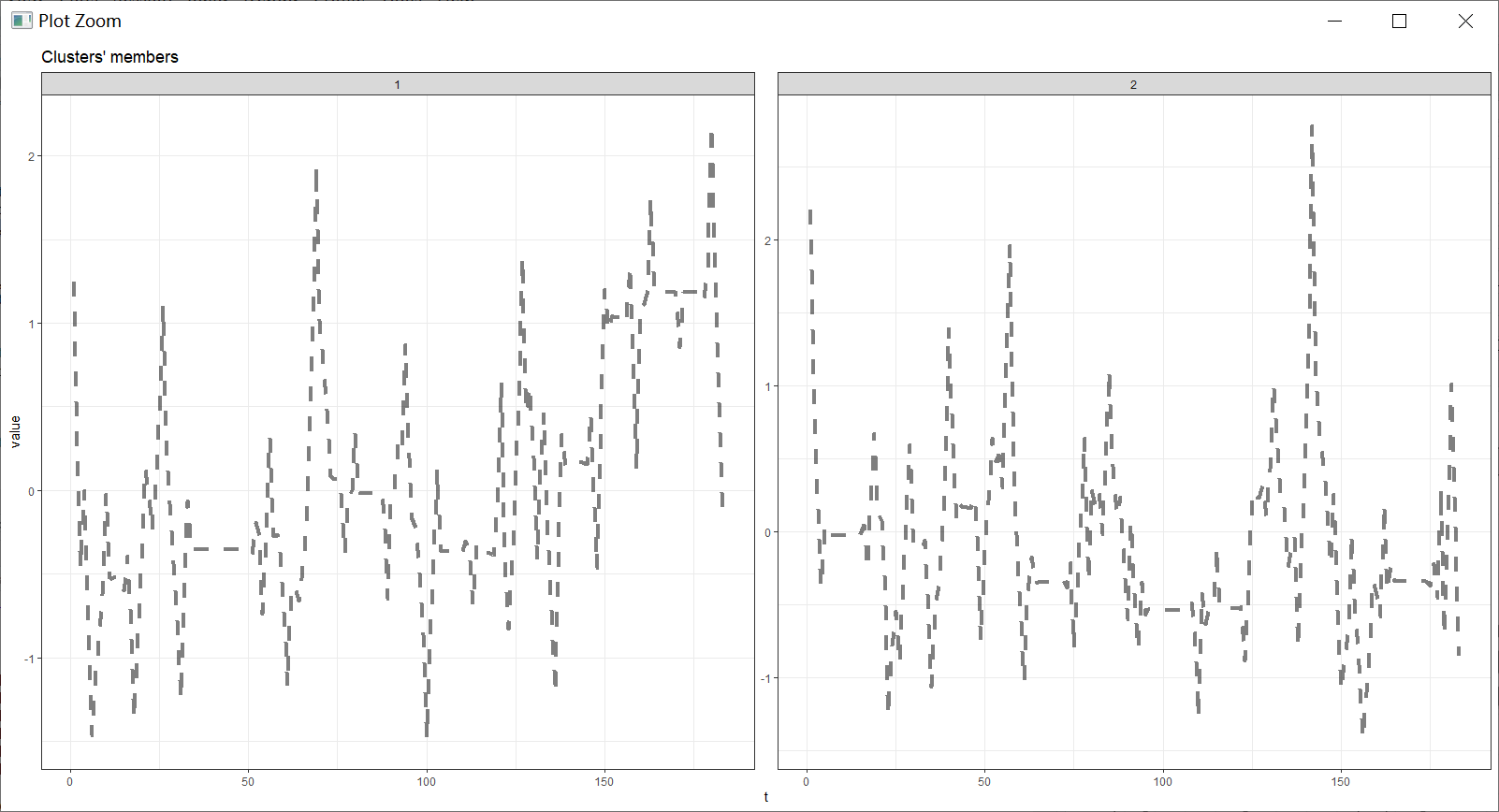 |
由图1、图2,第一个簇体的城市在后疫情时代有明显的复苏,而第二类簇体里面的城市则没有,甚至有消费金额下降的趋势。
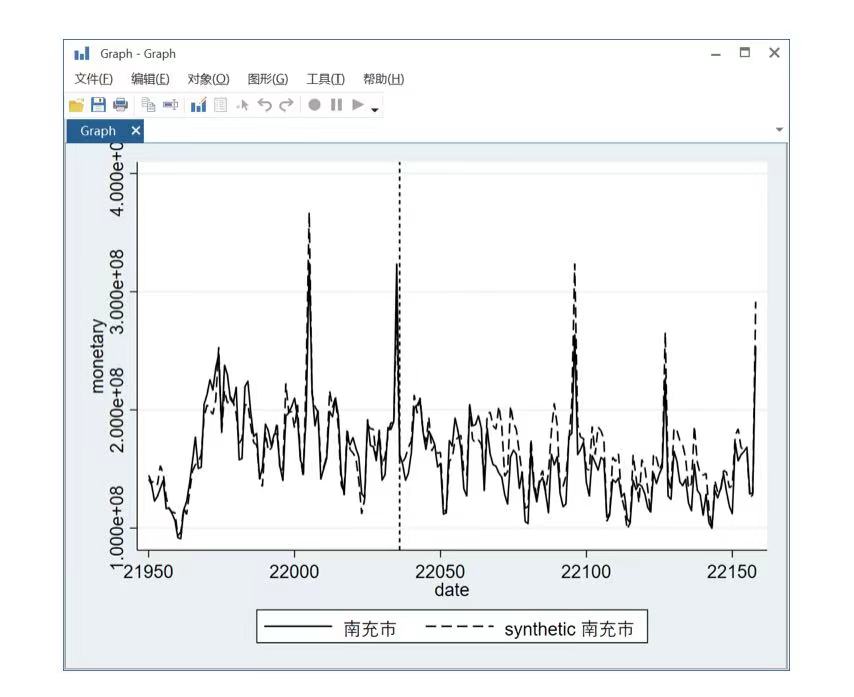
针对以上结果,我们选取南充市作为第二类簇体的代表城市,应用合成控制法对其进行分析。
 |
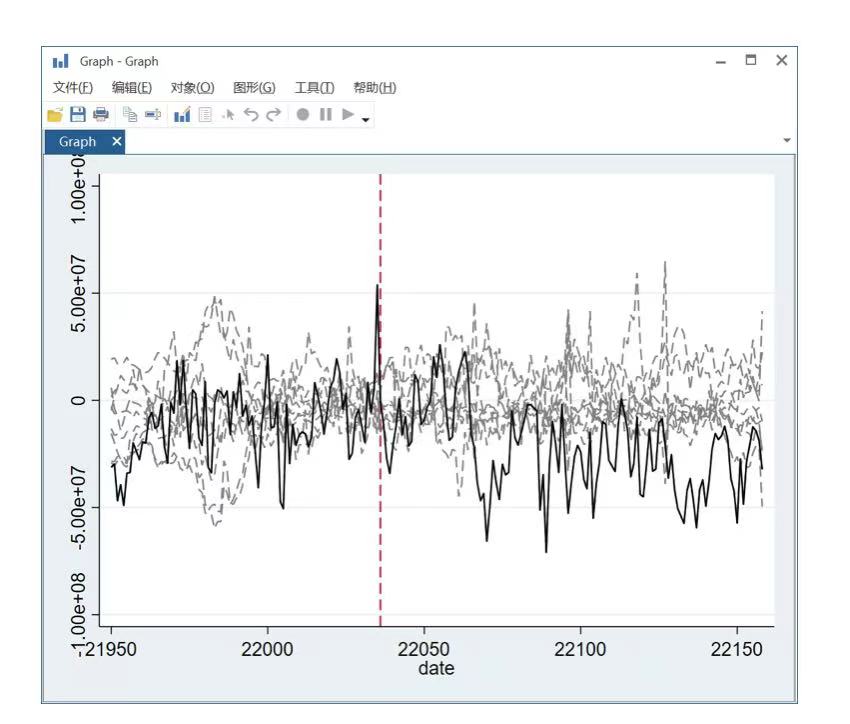 |
由图3, 合成的南充和真实的南充在5月1日(南充市发放消费券的起始日期)前高度吻合,而在5月1日后(南充市发放消费券起止日期为5月1日-8月31日),合成的南充在一段时间后明显要高于(大于)真实的南充的消费总金额。为保证结果严谨, 对其进行安慰剂检验,如图4。由图4,可以看到在5月1日前真实的南充和合成的南充的消费金额相减基本在0上下波动,而5月1日后相减得到的消费金额差在消费刺激刚开始的时候大于0之后明显小于0且比安慰剂组的其他城市都要小(从图上看南充(黑色线条)要比安慰剂组城市(灰色线条)要更低于0)